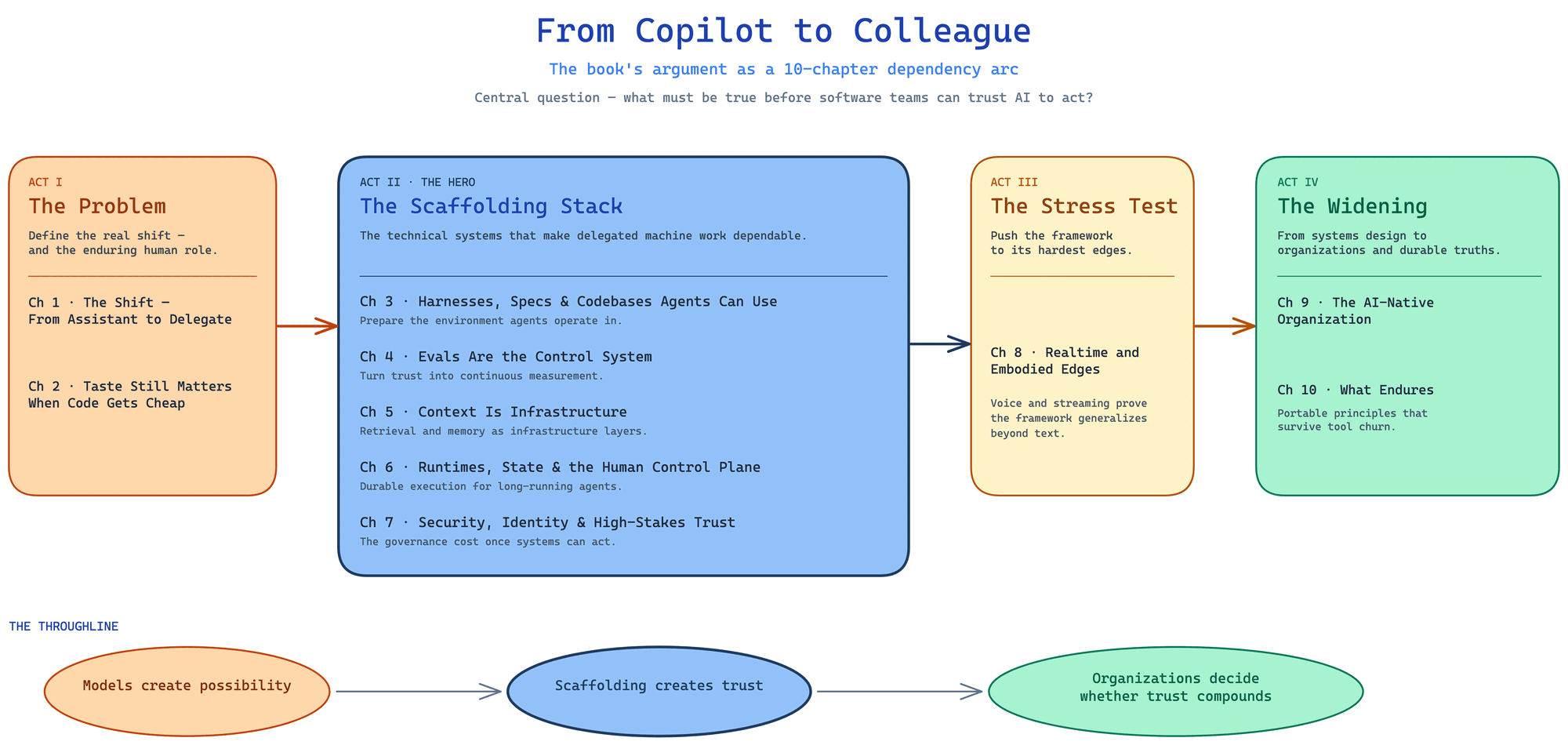
AI Engineer Book · Ch 01
The Shift: From Assistant to Delegate
FIG. 01.0 · OPENER
Assistant vs delegate
Click to enlarge
CH01
For a while, the most impressive thing AI could do was answer.
It answered faster than search, more fluently than documentation, and with just enough confidence to make people feel the future arriving inside a chat box. It could summarize a meeting, draft an email, explain a code snippet, brainstorm a launch plan, or produce a suspiciously polished first pass at almost anything. That mattered. It changed user expectations, product design, and the perceived shape of software. But it did not yet change the nature of work.
The deeper transition begins when the system is no longer asked only to suggest. It is asked to return with work done.
Research this market and come back with a memo. Review this contract and mark the risky clauses. Refactor this service, run the checks, and prepare the patch for review. Investigate the failure, trace the likely cause, and show me what to approve next.
That is a different standard. A helpful answer can be wrong and still useful. Delegated work is expensive in a different way. It consumes time, touches systems, shapes decisions, and often hides its mistakes inside output that looks plausible enough to pass a casual glance. That last property is the real trap: the primary failure surface is not the work that looks broken but the work that looks finished. The moment AI crosses from consultation into execution, eloquence stops being the main thing that matters, and the casual glance stops being an acceptable form of review. What matters is whether the system can produce bounded, inspectable, dependable work.
Joel Hron gives the cleanest formulation of this shift: the north star has moved “from helpfulness to productive.” In the same vein he describes the target as systems that don’t just suggest but plan their own work, execute it, and replan as they learn. That single move rearranges the field. Once we ask AI to actually produce output, make judgments, and act on behalf of users, the central problem is no longer prompt cleverness. It is trust under action.
That is the subject of this book. AI engineering begins where prompt engineering stops being enough. It is the discipline of turning raw model capability into delegated work that can be structured, measured, supervised, and trusted.
The real transition is from suggestion to delegation
A lot of confusion in AI discourse comes from flattening very different kinds of systems into one bucket. Calling everything an assistant or everything an agent blurs the distinction that actually matters.
The useful spectrum is simpler:
- an assistant suggests
- a copilot collaborates inside a tight human loop
- a delegate is given a unit of work and expected to come back with an artifact, a recommendation, or a completed step
The labels themselves are less important than the operating difference, and the cleanest way to tell them apart is to ask where the human sits relative to the loop: in the critical path for every step, alongside the work in real time, or out of the loop until review. An assistant helps you think; nothing it produces takes effect until you have read it. A copilot lands its contribution inside a task already in motion, the way it completes the line you were already typing. A steps you out of the moment-to-moment loop and back in at review, changing the state of the world even if only by producing work that others will rely on.
The book does not start with model intelligence in the abstract. Intelligence is necessary but insufficient. A system can be astonishing in conversation and still collapse the moment the user expects follow-through. Jacob Lauritzen, building legal AI at Legora, puts the break point bluntly: vertical AI and complex agents “need more than just the chat.” Sam Bhagwat makes the adjacent point from the workflow side. Once work becomes operational, the supposed opposition between agents and workflows starts to dissolve. The useful system is usually both.
That is the first throughline of : not better chat but delegated execution. And that shift matters because delegation changes the failure surface.
A suggestion can be ignored. A delegated action can create rework. A bad summary can waste a few minutes. A bad patch can stall a release. A shallow legal draft can mislead someone who assumes the system already did the hard part.
Chat is the visible surface; the real system lives underneath
The text box remains important. It is usually the easiest way for a human to assign work, redirect a trajectory, or inspect an intermediate result. But once the task horizon stretches beyond a single turn, chat stops being the whole system.
Chat is what people see. The real product is the machinery underneath.
A trustworthy needs:
- the right context, not just a large context window
- tools it can use without drowning in irrelevant options
- constraints that convert tacit expectations into explicit ones
- evaluation loops that catch drift before users do
- state that survives interruption, retries, and handoffs
- approval boundaries that let humans steer without micromanaging every move
- observability that shows what happened and what needs review next
This is why so many AI products keep escaping the chat box. They grow task lists, side panels, traces, approval queues, workflow views, memory layers, and tool catalogs. From the outside it can look like feature sprawl. Often it is something more basic: reality forcing the system to acquire a control surface equal to the work it to perform. Those organs are a diagnostic rather than decoration: when a serious agent product lacks one of them — a trace view, an approval queue — treat the absence as a reliability gap, not a leaner design, because a missing layer is usually where the workflow fails first. The important lesson is not that chat becomes irrelevant, but that it becomes one layer in a deeper stack.
That recurs throughout the book: as the around a coding agent, as evals and observability, as context assembly, as durable workflows and the . They are all answers to the same problem: what must surround intelligence before it is safe to work to it?
Capability is not the same as dependable work
The AI field keeps relearning a painful distinction: demo capability and operational dependability are not the same thing. A model can look extraordinary in a controlled interaction and still fail as a working system. It can write code that seems right but violates a local convention nobody wrote down. It can retrieve relevant documents but miss the one paragraph that actually governs the decision. It can produce a beautiful answer while silently losing track of what happened two steps ago. It can look productive and still be impossible to trust. That gap is what AI engineering exists to close.
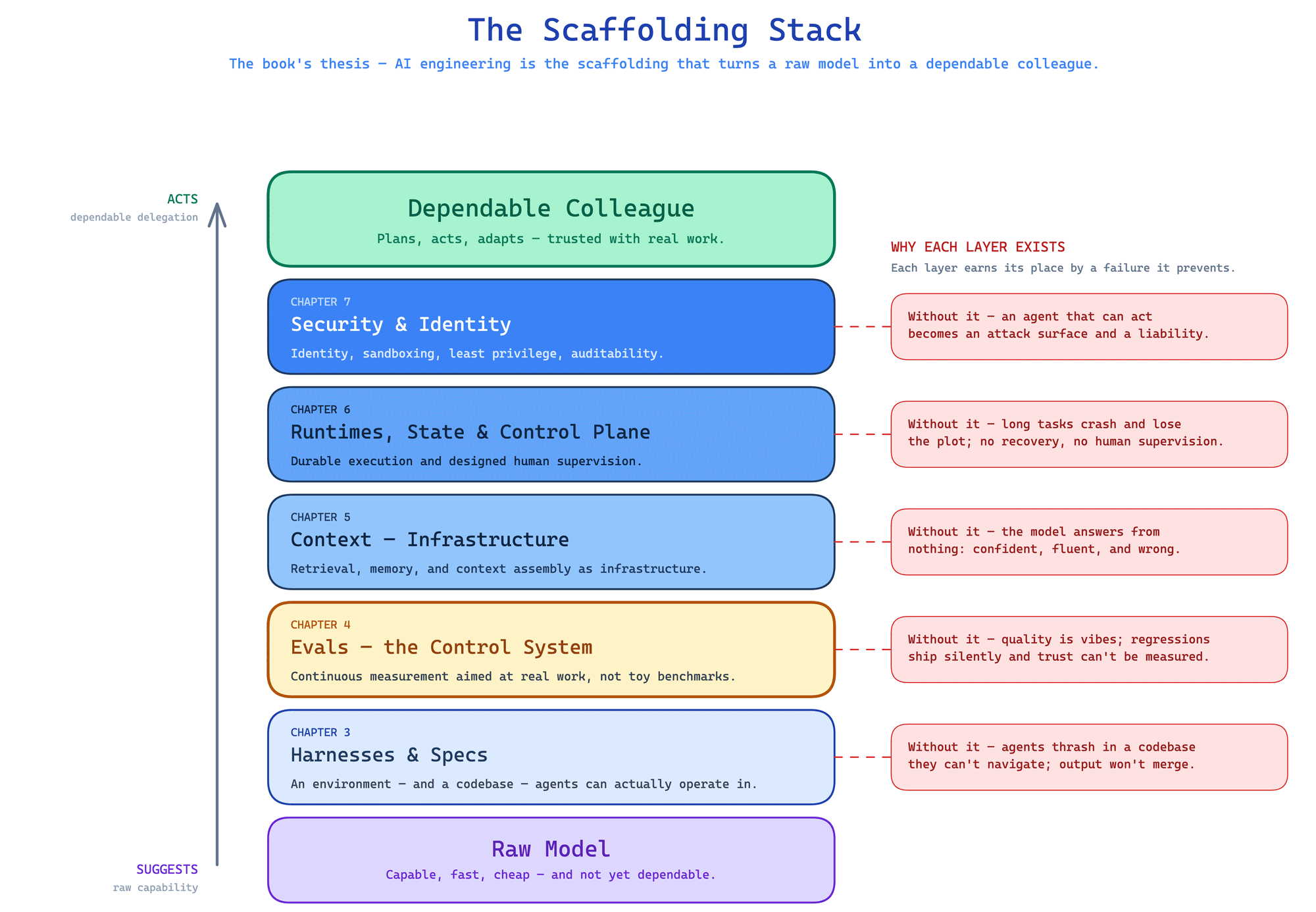
Barry Zhang and Mahesh Murag at Anthropic are especially useful here because they resist the fantasy that raw model progress alone solves the problem. Their formulation is careful: agents “have intelligence and capabilities, but not always expertise that we need for real work.” The illustration is exact — you would not ask a 300-IQ mathematician to derive the 2025 tax code from first principles when what you need is an experienced tax professional’s consistent execution. Capability and expertise are different things, and the practical move is to supply the second deliberately rather than wait for the first to grow into it: package the missing context, conventions, and procedures as reusable skills the agent can load. Models got dramatically more capable. Expertise gaps did not disappear. Operational gaps did not disappear. The principle underneath is that capability amplifies whatever workflow it runs inside: a stronger model makes a good system better and a weak one more dangerous, because it generates more convincing output whether the surrounding workflow is sound or broken.
This is one of the book’s strongest anti-hype : in production AI, scaffolding is not a wrapper around intelligence but what makes it usable. That line can sound deflationary until you notice how much leverage it creates. If dependable systems come less from raw cleverness than from the environment around the model, then engineering matters enormously. matter. Specs matter. Evals matter. Context architecture matters. Runtime semantics matter. Human oversight matters. The surrounding system is not bureaucratic drag on intelligence but the reason it can be trusted to do work.
The two recurring cases: the Software Factory and the High-Stakes Colleague
To keep this argument concrete, the book returns repeatedly to two recurring cases. Both are composite — drawn from real patterns rather than a single company — but they are consistent enough that what happens in one chapter carries into the next.
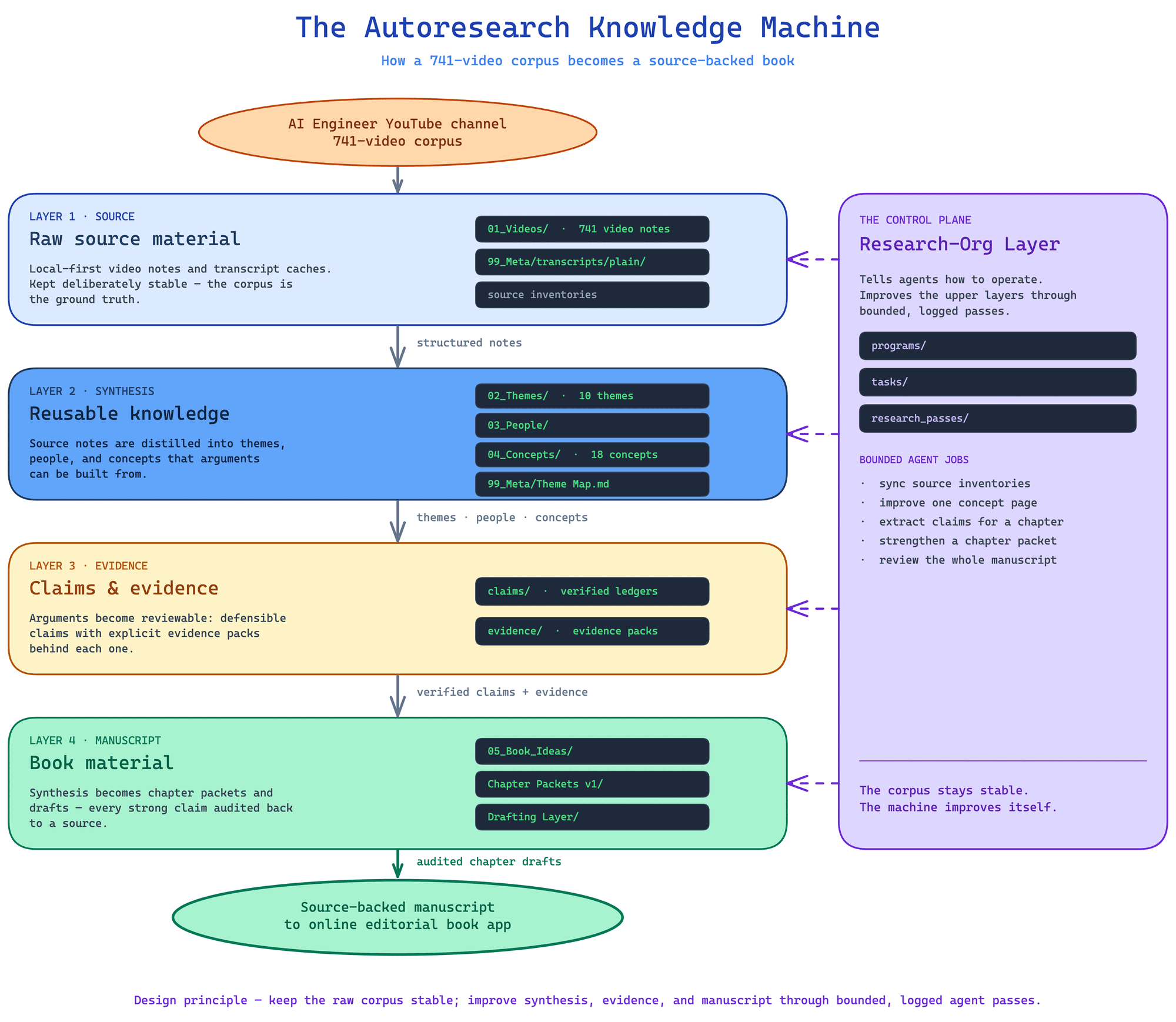
The first is the Software Factory, anchored in a company we will call Meridian. Meridian is a mid-size fintech. It starts with an ordinary payments repository and a strong coding model. At first the agent feels magical on small tasks. Then the team expands scope and quality gets erratic. The model is not always the real problem. The deeper issue is that the workplace was never made legible enough for delegated machine work. The team has to add , specs, validation, context discipline, eval loops, runtime structure, and review surfaces. As it does, the repo starts behaving less like a chat playground and more like a managed production environment for machine labor.
That case drives Chapters 3, 4, and 6 in particular. It shows how quickly "AI coding" stops being a prompt problem and becomes a systems problem.
The second is the High-Stakes Colleague, anchored in a firm we will call Hargrove. Hargrove is a mid-tier tax and advisory firm. Its assistant begins life as a helpful conversational surface that summarizes and explains. Then users ask it to do real professional work: assemble evidence, draft analysis, trace support, navigate internal knowledge, and operate under risk. Suddenly generic fluency is not enough. The system needs provenance, access boundaries, retrieval discipline, staged authority, durable trajectories, and explicit review points. It is no longer being judged as an answer engine. It is being judged as a professional .
That case becomes especially important in Chapters 5, 6, and 7. It makes the trust question impossible to romanticize. In higher-stakes domains, "almost right" is often the most dangerous category.
These two cases matter because they prevent the opening from floating above the rest of . The book is not arguing in abstractions; it is following the same transition across two kinds of work:
- one where the output is software
- one where the output is high-stakes professional judgment
In both, the same pattern appears. The more valuable the delegated work becomes, the more the surrounding system starts to matter.
Delegation makes hidden judgment visible
There is a second reason the opening cannot be only about tools and architecture. Delegation exposes how much good work always depended on tacit human judgment.
In the software case, that means local conventions, architecture taste, dependency discipline, rollback instinct, performance habits, and dozens of non-functional expectations that senior engineers usually carry in their heads. In the professional-services case, it means source hierarchy, provenance awareness, exception handling, domain caution, and judgment about when a result is not ready to trust.
Humans often mistake this tacit judgment for natural background competence because strong teams internalize it so thoroughly. But once work is handed to a machine collaborator, hidden standards become a liability. The system cannot reliably inherit what the organization never externalized, which sets the practical rule: a standard has to be made explicit before it can be delegated, or it will be violated silently. The opening of the book needs a second alongside the delegation : cheap generation increases the value of judgment.
When code, prose, research notes, and drafts get cheaper to produce, taste does not become obsolete. It becomes more operationally important. The new scarce skill is not typing faster. It is setting standards, framing tasks, spotting slop, and knowing what good looks like before the system does.
If Chapter 1 asks what changes when execution becomes delegable, Chapter 2 asks what humans still have to be excellent at when generation becomes abundant. The answer is not less craft but more visible craft.
AI engineering is the discipline of making delegation trustworthy
Once you accept that the real shift is from suggestion to delegation, a lot of the surrounding field stops looking fragmented. Prompting, retrieval, evals, workflow engines, guardrails, tool protocols, observability, sandboxing, policy files, and approval systems are often discussed as if they were separate subcultures. They are not. They are pieces of one broader discipline: making delegated machine work trustworthy enough to use.
That discipline keeps returning to a small set of questions. Can the system understand the environment it is supposed to operate in? Are the goals and constraints externalized well enough to survive handoff? Can the team tell whether the system is actually doing useful work? Is the model seeing the right information, in the right shape, at the right time? Can the work persist, recover, and expose itself to human supervision over time? Where should the system be free to act, and where must human judgment remain decisive?
AI engineering deserves to be treated as more than prompt craft or model selection. It is closer to distributed systems, product design, operations, and organizational design fused together around probabilistic components. Once the model is expected to do work, every surrounding layer becomes part of the product.
Trust under action is the governing problem
This book is not organized around the question of whether models are impressive. They are. It is not organized around whether chat is useful. It is. It is organized around a harder question: under what conditions can a system act or produce on behalf of a user without quietly drifting out of bounds?
That is the governing problem because action changes everything. A product that only converses can survive with soft trust. A product that drafts, edits, executes, routes, retrieves, summarizes, recommends, or mutates real systems needs harder trust. It needs state, structure, reviewability, and control.
The book is also skeptical of autonomy maximalism. The goal is not to maximize agency in every direction. In many valuable systems, the right design is adjustable autonomy: let the machine move quickly where the risk is low and the checks are strong; slow it down where consequences are harder to reverse. Useful autonomy is not max autonomy but well-tuned autonomy.
The opening should already make one thing clear: trust in AI is not mainly a matter of anthropomorphism or vibes. It is a property of system design.
What the rest of the book is really about
The chapters that follow are not a tour of trendy infrastructure. They are a cumulative answer to the same opening question.
- Chapter 2 asks what human craft becomes more valuable when execution gets cheap.
- Chapter 3 shows that delegated coding lives or dies on the legibility of the repo and the around it.
- Chapter 4 argues that delegated systems need a control loop, not just a few impressive successes.
- Chapter 5 argues that useful intelligence depends on building the right active working set, not merely shoveling more tokens into a window.
- Chapter 6 argues that long-running delegated work needs state, runtime semantics, and a .
- Later chapters extend the same logic into security, identity, realtime edges, and organizational redesign.
The underlying argument is continuous even when the technical surfaces change. The future of AI engineering is the gradual construction of dependable shared systems in which humans steer, machines execute, and trust is earned through architecture, not a pile of isolated tricks.
Closing move
The most important fact about modern AI is not that it can talk. It is that people increasingly want it to work.
They want it to return with artifacts, not just ideas; with completed steps, not just suggestions; with trajectories that can be inspected, redirected, and trusted. That desire raises the standard for the whole stack. A useful needs context, structure, evaluation, durable state, and supervision. It needs engineering.
The rest of this book is about what happens once we take that requirement seriously.
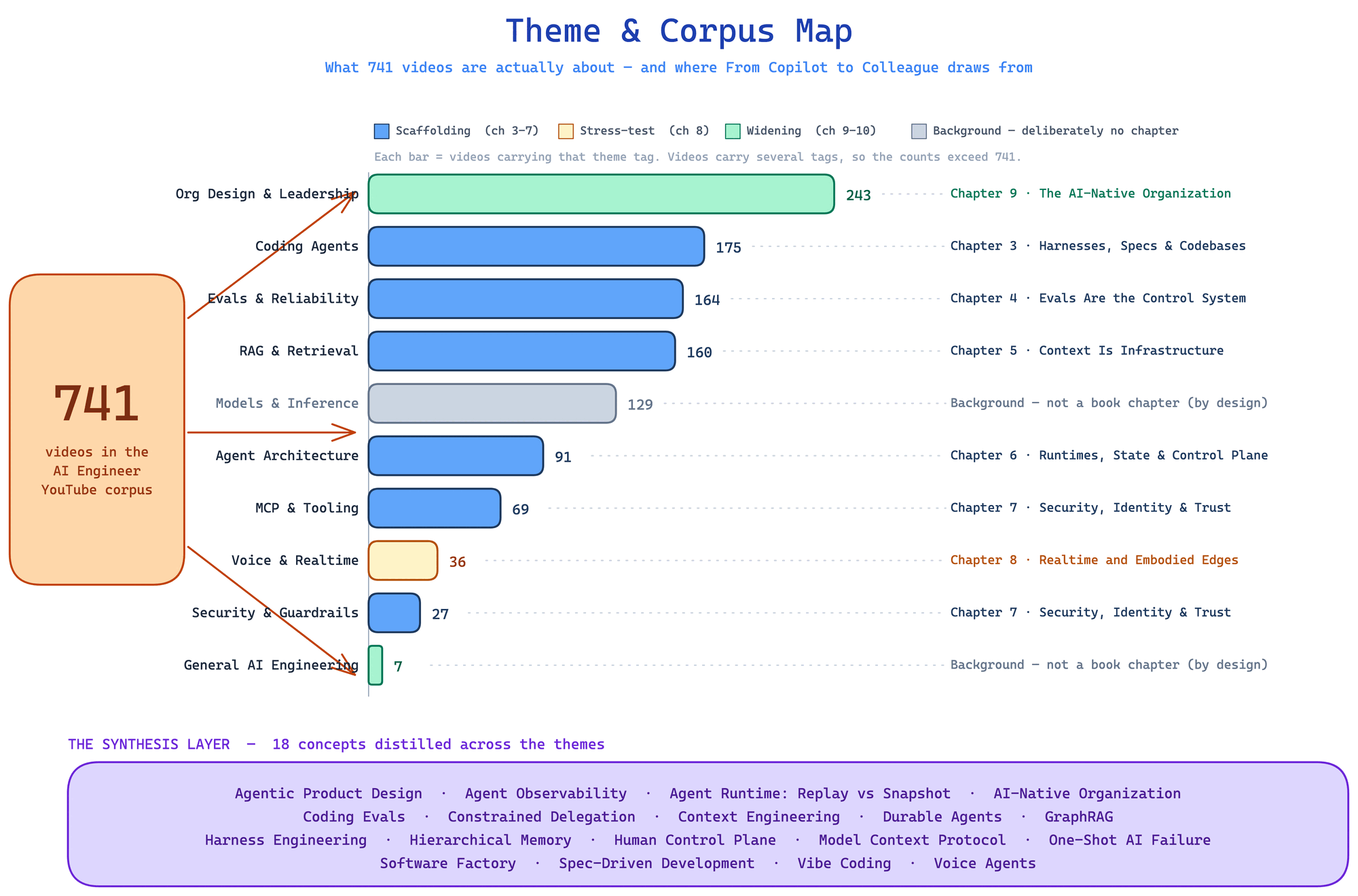
5 claims · 16 source anchors
Evidence — Source Anchors
The important transition is from suggestion to delegated execution
Open in graph“from helpfulness to productive”
#206 — Joel Hron, Thomson Reutersconfidence: high“I think they need more”
#3 — Jacob Lauritzen, Legoraconfidence: high“most primitives the magic happens when you combine these things together”
#138 — Sam Bhagwat, Mastra.aiconfidence: high
Chat is an insufficient control surface for long-running or high-stakes work
Open in graph“Chat is one-dimensional. It's a very low bandwidth interface,”
#3 — Jacob Lauritzen, Legoraconfidence: high“we're asking AI systems to now produce output and produce judgments and decisions”
#206 — Joel Hron, Thomson Reutersconfidence: high“handle state potentially over long periods of time. There needs to be human interaction for approvals”
#167 — Preeti Somal, Temporalconfidence: high
Reliability comes less from model cleverness than from surrounding scaffolding
Open in graph“The important thing is not the code but the prompt and the guardrails that got you there.”
#16 — Ryan Lopopolo, OpenAIconfidence: high“Agents have intelligence and capabilities, but not always expertise that we need for real work.”
#83 — Barry Zhang & Mahesh Murag, Anthropicconfidence: high“these are three kind of like ingredients which are pretty simple and pretty basic, but I think provide an interesting kind of like first principles approach for how to think about”
#198 — Harrison Chase, LangChain/LangGraphconfidence: high
Human oversight works best as an architectural layer, not an afterthought
Open in graph“There needs to be human interaction for approvals or other reasons and of course they need to be able to be uh able to run in parallel for efficiency”
#167 — Preeti Somal, Temporalconfidence: high“dial these agency dials far up.”
#206 — Joel Hron, Thomson Reutersconfidence: high“maintaining a factory would require you to have an overview of the processes you want your coding agents to go through.”
#629 — Eric Zakariasson, Cursorconfidence: high
Once agents go parallel and autonomous, the human's verification capacity — not the agents' generation capacity — is the binding constraint
Open in graph“agents are not the bottleneck now and I think that's going to increasingly be the case, but we are.”
#761 — Zack Proser, WorkOSconfidence: high“our attention is still, you know, in meatspace, if you will, and it still degrades under load. It's still the hard constraint, essentially.”
#761 — Zack Proser, WorkOSconfidence: high“we just want you to look at PRs that are ready for you in GitHub.”
#758 — Joshua Snyder, PostHogconfidence: high“instead of you reviewing changes, if the change is pretty easy, let's just approve it with an agent and deploy it behind a feature flag.”
#758 — Joshua Snyder, PostHogconfidence: high
scored on version git:e68466c